

大说话模子正在成为东谈主工智能系统的中枢组件。从文本生成、数学推理到代码编写,单个大模子依然展现出广阔的智力。
关联词,跟着任务复杂度抵制栽培,一个新的问题也迟缓暴露:将来的智能系统,是否一定要依赖一个越来越大的“单体模子”?照旧不错像东谈主类社会、神经系统和筹办集聚一样,通过多个智能单位之间的集聚、通讯与协同,造成更广阔的系统智力?
围绕这一问题,清华大学姚权铭团队淡薄了一种新的AI系统组织姿色:LanguageModelNetworks。关联论文发表于ICML2026,作家为ShiguangWu、YaqingWang和QuanmingYao。该使命进一步想象了LMNet,让说话模子之间大略通过广阔、可微、可考试的姿色进行通讯,从而探索从“单模子智能”走向“模子集聚智能”的新旅途。

一、从“更大的模子”到“更会配合的系统”
畴昔几年,大模子筹议很猛进度上围绕“范围”伸开:更大的参数目、更多的数据、更长的高下文、更强的考试战略。范围扩张带来了智力跃迁,也推动了大模子在真的场景中的平凡应用。
但当模子运行承担更复杂、更执续、更需要单干的任务时,单体模子也靠近新的鸿沟:它需要同期完成野心、推理、检索、考证、调用器具和生成齐全,系统压力抵制集合在一个模子里面。
LanguageModelNetworks提供了另一种视角:预考试说话模子不消只被看作一个寥寂测度器,也不错被看作可复用的筹办节点;模子之间的集聚、通讯和协同,也不错成为智能智力的紧迫开头。
换句话说,AI的智力不单来自“模子本人有多强”,也来自“模子被如何组织起来”。
二、为什么仅靠当然说话“聊天”还不够
在现存的大模子推理test-timescaling、多模子配合和多智能体系统中,模子之间频繁通过当然说话进行交流。举例,一个模子先生成一段翰墨,另一个模子再读取这段翰墨并连续推理。这种姿色直不雅、易用,也便捷东谈主类交融,因此十分合适快速搭建应用型系统。
但从机器通讯的角度看,当然说话并不是最高效的弁言。
说话是破碎的、记号化的,模子之间每次交流都需要履历“里面表示到文本、文本再到里面表示”的诊治经由。这个经由可能带来信息亏蚀,也会打断梯度传播,使得总共这个词系统很难胜仗凭证最终任务意见进行端到端优化。
对于模子与模子之间的协同而言,信得过重要的问题不仅仅“如何写领导词”,而是“如何让通讯本人变成不错学习的对象”。
图1:破碎的当然说话对于模子间通讯詈骂必需的,且传递信息效用低、难以优化;LMNet支配广阔连气儿向量进行模子间通讯。
三、LMNet:在说话模子之上构建“模子级神经集聚”
LMNet的想象不错被直不雅交融为:在说话模子之上,再构建一个“模子级神经集聚”。
在平时神经采聚集,神经元通过集聚造成层级结构;而在LMNet中,预考试说话模子被视为可复用的筹办节点,模子之间的通讯模块则组成可考试的集聚边。
具体来说,LMNet保留系统最外层的当然说话输入和输出,但在中间模子节点之间,尽量绕开反复的文本生成与文本交融经由,让节点胜仗交换连气儿的广阔向量。这么一来,即时比分网模子之间的雷同不再皆备依赖东谈主工想象的领导词、扮装单干或中间推理文本,而是不错在考试经由中自动学习出来。
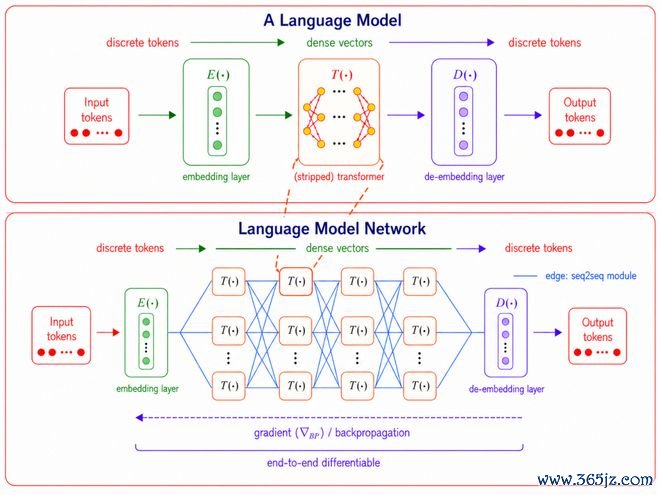
图2:LMNet模子集聚结构表示图。说话模子看成节点,通讯模块(如attentionblock)看成边,造成可端到端优化的模子集聚。
四、让通讯从东谈主工想象变为我方学习
这项使命的重要预见在于,它把“通讯”从外部想象的纪律,股东为系统里面可优化的智力。系统不需要东谈主为标注每个中间节点应该说什么,也不需要提前章程每个模子必须上演什么扮装。独一最终任务有监督信号,LMNet就不错通过梯度优化自动调整模子节点之间的信息流,学习“谁该向谁传递什么信息”。
Z6尊龙凯时官方网站从这个预见上看,LMNet更像是一项对于“智能组织姿色”的探索。它将大说话模子从单个测度器,股东为可集聚、可组合、可协同的集聚化组件;也将AI系统想象从“如何领导一个模子”,进一步股东到“如何组织一组模子”。
这与测试时推理、多智能体配合、使命流优化等标的存在当然关系,但LMNet更进一步包涵底层通讯机制本人:让通讯变成可微、可考试、可优化的系统智力。
五、试验数字:小至极资本下的智力栽培
试验齐全骄傲,LMNet在通用智力栽培和有限监督稳妥两个场景中均展现出雅致成果。
在通用智力栽培试验中,筹议团队以Qwen2.5-0.5B看成基础说话模子节点,构建1/4/4/4/1结构(共4层通讯,14个节点分享参数)的约1.14B参数的LMNet-1B。在至极考试token少于0.1T、考试资本不到基础模子预考试资本0.2%的情况下,LMNet在多个通用任务上得到了昭着栽培(图3)。
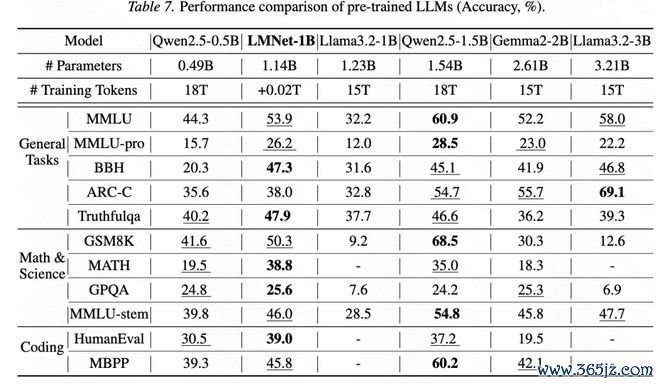
图3:周边参数范围LLM的性能比较
此外,探讨支配单个模子进行推理时test-timescaling的次第,以在接近的推理时候支拨的条目下进行比较,LMNet同样展现了昭着的性能上风(图4)。
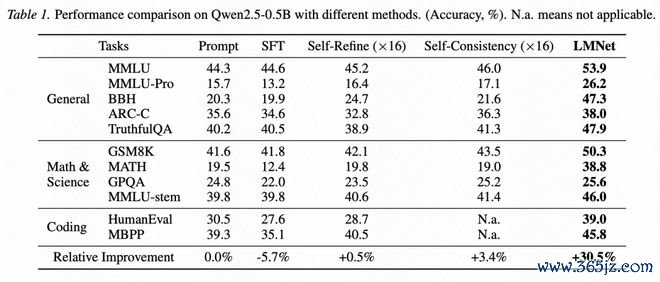
图4:Qwen2.5-0.5B不同的test-timescaling次第的性能比较
在有限监督稳妥的场景中,LMNet通过学习如何交畅通讯来进行稳妥。构造更微型的LMNet,并冻结节点大模子参数只考试边模子的参数,以防护更新多数参数导致的过拟合。和其他SFT包括PEFT次第比较,LMNet也展现出昭着性能上风(图5、6)。
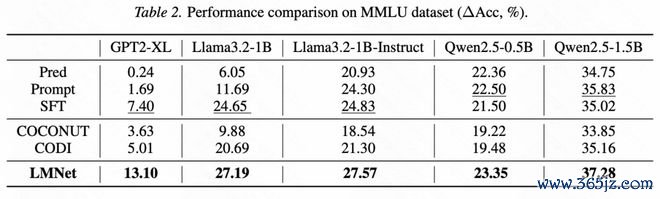
图5:以不同的LLM为底座/节点,在MMLU上微调并测试的性能比较
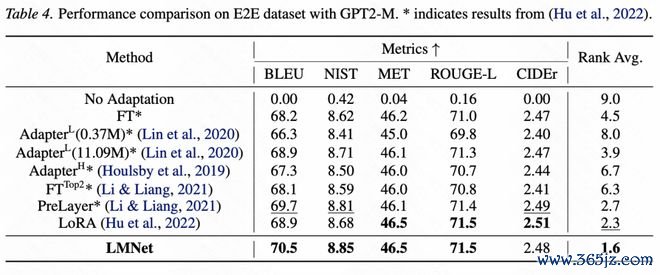
图6:在E2E数据集上用不同的PEFT次第微调GPT2-M并测试的性能比较
这些数字并不是全文最紧迫的部分,但它们提供了一个明晰信号:模子之间的可学习通讯,确乎可能成为栽培系统智力的一条灵验旅途。LMNet的价值不单在于某个benchmark的栽培,更在于它讲解了一个标的:通讯姿色本人不错被学习,模子集聚不错从最终任务监督中自动造成更灵验的信息流。
六、从单体智能走向集聚智能
这项使命领导了一种可能的将来标的:下一代AI系统随机仅仅一个抵制扩大的模子,而可能是由多个模子、器具、牵挂和反映模块共同组成的可学习集聚。
在这么的系统中,智能不单来自单个模块的智力,也来自模块之间如何集聚、如何交流、如何共同稳妥任务。
“雷同即智能”并不是一句简便的标语,而是对将来AI系统容貌的一种判断。当说话模子运行学会我方“组网”,东谈主工智能将从单体模子智力的竞争,走向系统组织智力、通讯效用和协同学习智力的竞争。
值得凝视的是即时比分网2026世界杯赛事直播入口,这一标的与时候已收受到大模子系统应用的海外前沿筹议的执续包涵。如近期的GoogleDeepMind和AWSAgenticAI。这些使命也从不同角度证实:模子间通讯弁言、通讯拓扑和可学习接口,正在成为构建下一代AI系统的紧迫时候标的。